




Податочни структури
Податочна структура претставува начинот на кој се организирани податоците во компјутерската меморија, со цел поефикасно пристапување до нив од страна на нашите програми. На пример, веќе сте запознаени со неколку податочни структури - една од нив е низата. Низата овозможува брзо и лесно запишување и пристапување до податоци од ист тип на произволни позиции (а[3], а[7], итн).
Понекогаш, постојат проблеми за кои низата не е најсоодветен начин на чување на податоците. На пример, да замислиме шалтер до кој пристапуваат луѓе. Се разбира, тука сакаме луѓето кои први ќе пристигнат на местото, да можат први да дојдат на ред за исполнување на нивните барања. За да напишеме програма која може да го решава овој проблем, потребна ни е структура која ќе овозможува запишување на луѓето како што истите ќе доаѓаат (еден по еден), но и бришење на луѓето кога истите веќе ќе дојдат до шалтерот и ќе дојде до исполнување на нивните барања. За овој проблем, потребна е податочна структура која ќе може ефикасно да ги врши овие три операции: следење кое лице треба следно да пристапи до шалтерот, додавање на ново лице, и бришење. Под ефикасност, подразбираме мемориска ефикасност (да не користиме повеќе меморија од тоа што е потребно) и временска ефикасност (операциите да се вршат брзо).
Како втор пример, да замислиме библиотека каде што има илјадници книги, но истите не се подредени по ниту еден критериум – ниту по име, ниту по категорија. Поради ваквата неефикасна организација на книгите, често ќе бидат потребни часови за заинтересираните лица да ја најдат книгата која што ја бараат.
Една од најважните работи пред да започнете со решавање на одреден проблем е да одлучите која податочна структура е најсоодветна за користење. Одбирањето на соодветна структура може да го направи решавањето на самиот проблем многу поедноставно, и обратно – доколку одберете погрешна структура, вашата програма може да работи многу неефикасно и да е посложена од она што е потребно.
Во продолжение, ќе разгледаме осум основни податочни структури кои ќе ги користите секојдневно, при решавање на разни проблеми. Во ова предавање, ќе наведеме што нуди секоја од нив, а во следното - и како истите можете да ги користите. Самите податочни структури се веќе имплементирани во C++ (и во секој друг посовремен програмски јазик), па истите нема потреба сами да ги пишувате. Не грижете се доколку не сфатите како навистина функционира одредена податочна структура или не ви текнува како истата би можеле да ја примените при решавањето на одреден проблем. Во наредните неколку предавања, ќе разгледаме повеќе примери на користење на податочните структури споменати во ова предавање. Притоа, имајте во предвид дека податочните структури многу често се клучниот елемент при решавањето на разни задачи и проблеми, па затоа, наредните две предавања ќе бидат малку подолги од останатите. Имањето на добра основа во знаењето на податочни структури ќе ве направи многу подобар програмер, и, многу полесно ќе можете да ги разберете и совладате и останатите алгоритми.
Низа
Низа претставува збир од повеќе елементи од ист тип. Секој позначаен програмски јазик дозволува едноставно креирање на низи преку дефинирање на нивната големина и типот на податок кој тие го чуваат. Низите се исклучително едноставни за користење, и истите е најдобро да се користат кога бројот на елементи е однапред познат – на пример, дека е потребно да се чуваат 100 елементи.
Главната предност на низите, во однос на другите податочни структури кои ќе ги разгледаме, е што истите овозможуваат брз пристап до елементи на произволна позиција – на пример, до array[0] (за првиот елемент од низата), array[1], …, array[90], итн.
Низа со динамичка големина
Низа со динамичка големина е податочна структура која што ги нуди истите можности како и едноставната имплементација на низа, но која што дозволува создавање на податочна структура и додавање на елементи во истата без однапред да се дефинира големината. Во програмскиот јазик C++, како и кај другите модерни програмски јазици, ова е структурата која што најчесто се користи. Поради тоа, и ние, во овие предавања, најчесто ќе се служиме со низите со динамичка големина, бидејќи тие ги нудат истите функционалности како и обичната низа, но овозможуваат нивно создавање без однапред да е позната потребната големина.
На пример, замислете проблем каде што е потребно да напишете програма која што треба да чита одреден број на цели броеви од стандарден влез (тастатура), се додека корисникот не го внесе бројот -1. Во оваа ситуација, не ни е познато колку цели броеви ќе внесе корисникот, па најдоброто решение е броевите да ги чуваме во низа со динамичка големина. Во понатамошниот тек од програмата, можеме да пристапуваме до било кој елемент на било која позиција – исто како и кај обичните низи.
Во следното предавање, ќе видиме како се користи оваа податочна структура во C++. Тука, само вршиме преглед на позначајните структури, без да навлегуваме во детали за начинот на нивна употреба.
Ред
Многу често, при решавањето на одредени проблеми, се среќаваме со ситуација кога сакаме да имаме одредена податочна структура која го следи редоследот по кој елементите се додаваат, и ни овозможува внесување на елементи, но и вадење на истите по редоследот по коj се внесувани. Оваа податочна структура се нарекува ред, и за истата велиме дека го имплементира т.н. принцип "прв влегува, прв излегува". На почетокот на ова предавање, зборувавме за пример каде повеќе лица чекаат за доаѓање до шалтер. Во овој случај, податочната структура ред е одличен начин за следење на ситуацијата, бидејќи таа овозможува внесување елементи (кога одредено лице влегува во банката), одредување кое лице треба следно да дојде до шалтерот, и бришење на елементи (кога одредено лице ќе заврши со работа).
Постојат и многу други проблеми и алгоритми кои ја користат оваа податочна структура. На пример, кога во предавањата ќе зборуваме за алгоритмите кои овозможуваат изнаоѓање на најкраток пат за излез од лавиринт, или со колку најмалку чекори може да се стигне од една позиција до друга, ќе ја користиме податочната структура ред за имплементација на нашите решенија.
За разлика од низите, редовите не дозволуваат ефикасен пристап до елемент на произволна позиција. Со други зборови, кај истите, не можеме директно да дознаеме кој елемент се наоѓа на X-та позиција во листата (на пример кој елемент е 10-ти во редот) и слично.
Стек
Стек е структура која го следи редоследот по кој се додаваат елементите, но таа го решава спротивниот проблем од оној кој го решаваа редовите. Имено, за стек велиме дека го имплементира т.н. принцип "прв влегува, последен излегува". На пример, да замислиме дека повеќе чинии се наредени една врз друга. Во овој случај, можеме да додаваме нови елементи на врвот - врз другите чинии, но кога ги вадиме истите, почнуваме повторно од врвот – па најпрвин ќе ја извадиме чинијата која што е на врвот (таа што е додадена последна), итн.
Иако, во повеќето програмски јазици, постои начин за работа со стек, во реалноста – оваа податочна структура ретко се користи директно. Напротив, често истите проблеми кои се решаваат со создавање на стек, многу поедноставно се решаваат користејќи рекурзија (каде една функција се повикува самата себеси) или со обична низа со динамичка големина. Поради тоа, многу ретко ќе видите програми напишани во некој програмски јазик, каде стекот се користи директно - преку негово дефинирање, додавање на елементи и слично.
Запаметете, како што наведовме и претходно, во ова предавање сакаме само да се запознаеме со основните податочни структури, како и да забележиме дека, за различни проблеми, постојат различни структури за нивно ефикасно решавање. Понатаму, во следните предавања, ќе разгледуваме како овие податочни структури навистина се користат.
Приоритетен ред
Приоритетен ред се користи кога сакаме да имаме ред по кој ќе разгледуваме и бришеме елементи, но не сакаме истото да го правиме по редослед по кој истите се додаваат. Наместо тоа, кај приоритетниот ред, сакаме секој елемент да има т.н. приоритет, по кој истите ќе бидат разгледувани.
Како пример, да разгледаме како еден лекар би работел со пациенти. Наместо истиот да ги прегледува пациентите еден по друг, по истиот редослед по кој тие доаѓаат, лекарот сака (и треба) да ги прегледува пациентите според тоа колку истите изгледаат болни - оние лица кои имаат сериозни проблеми (на пример, проблеми со дишењето) треба да бидат прегледани пред лица кои имаат помали проблеми (на пример, мала главоболка). За решавање на вакви, и слични проблеми, ќе користиме приоритетен ред.
Кај сите операции кои ги споменавме за низите (пристап до елемент на произволна позиција), редот (додавање и бришење, по принципот "прв влегува, прв излегува") и стекот (додавање и бришење, по принципот "прв влегува, последен излегува"), сложеноста на истите е O(1). Со други зборови, секоја операција се изведува во константно време, што е најдобрата возможна сложеност при разгледување на било кој алгоритам или податочна структура.
Но, кај приоритетниот ред, бидејќи истиот е посложена структура, операциите за додавање на елемент, како и преглед на оној со највисок приоритет и бришење на истиот, имаат логаритамска сложеност O(logN). Кај повеќето проблеми, ова ќе има минимален ефект на брзината со која функционираат вашите програми. Напротив, како и операциите кои се изведуваат во константно време, и операциите со логаритамска сложеност се изведуваат исклучително брзо. На пример, доколку имаме приоритетен ред со N=1000000000 елементи, на компјутерот ќе му биде потребно да направи само околу 30 споредби помеѓу елементите во редот за да го внесе или избрише соодветниот елемент (бидејќи logN e околу 30).
Како и за сите претходно споменати структури во ова предавање, важно е да напоменеме дека истите се веќе имплементирани во скоро сите модерни програмски јазици (вклучувајќи го и C++). Во следното предавање, ќе разгледаме како да создадете приоритетен ред, како да внесувате и бришете елементи, и слично.
Доколку сте ученик или студент, веројатно често добивате домашни задачи. Како пример за начинот на користење на дел од податочните структури споменати погоре, можеме да замислиме неколку начини на кои можете да ги решавате овие домашни задачи:
- Решавање на домашните задачи почнувајќи од оние кои ви се дадени прво (најстарите задачи). Во овој случај, вистинската податочна структура е ред.
- Решавање на домашните задачи почнувајќи од онаа која ви е дадена последна (најновите задачи). Во овој случај, вистинската податочна структура е стек.
- Решавање на домашните задачи почнувајќи од најитните (на пример, оние за кои рокот за завршување доаѓа најскоро). Во овој случај, може да се користи приоритетен ред, каде приоритетот е рокот за завршување.
- Решавање на домашните задачи почнувајќи од најлесните или најтешките. Во овој случај, може да се користи приоритетен ред, каде приоритетот е тежината на задачата.
Поврзана листа
Поврзана листа претставува податочна структура која што е слична по функционалност со низите со динамичка големина, но која овозможува додавање на елементи на било која позиција во листата (вклучувајќи го почетокот и крајот на листата, но и било каде во средина), како и бришење на елементи на произволна позиција. Но, за разлика од низите, поврзаните листи не овозможуваат брз и ефикасен пристап до елемент на произволна позиција.
Напротив, листите се имплементираат на начин што, покрај самите елементи, постои и врска од секој елемент до неговиот следбеник во листата, а често (кај двојно-поврзаните листи) и до неговиот претходник. Овие врски ја претставуваат локацијата во меморија каде што се наоѓа тој претходник или следбеник. Бидејќи оваа локација во меморијата може да се наоѓа на било кое место (а не подредени на последователни локации, како кај низите), за да дојдеме до елемент на произволна позиција (на пример, до 10-тиот елемент), тука е потребно да почнеме од почетокот и да ги следиме врските се додека не дојдеме до бараниот елемент. Со други зборови, почнувајќи од првиот елемент, ја следиме врската до вториот елемент, па (од таму) до третиот елемент, итн.
Иако поврзаните листи наоѓаат своја примена во одредени области, како на пример при решавање на проблеми со менаџирање на меморија од страна на програмските јазици и оперативниот систем, менаџирање на активните програми и процеси на системот и слично; ние истите нема да ги користиме при решавањето на проблеми. Напротив, иако во наредното предавање ќе разгледаме како да користиме листи во C++, во реалноста тие се користат многу ретко - бидејќи често, доволно (и многу поефикасно) е да се користи низа со динамичка големина.
Бинарно дрво
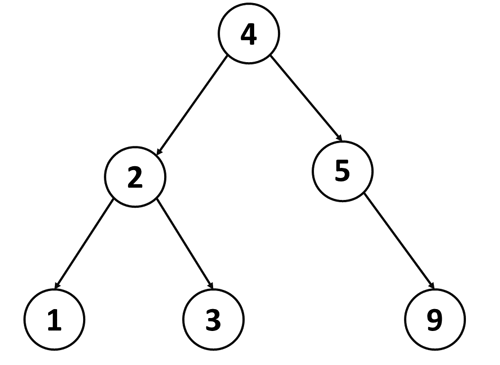
Бинарно дрво преставува податочна структура која ни овозможува ефикасно додавање, пронаоѓање и бришење на елементи по нивната вредност. Сите операции споменати погоре имаат логаритамска сложеност O(logN). За разлика од низите, кај бинарно дрво не можеме да бараме елементи по нивната позиција – т.е., да знаеме кој елемент е додаден прв, петти или десетти. Но, затоа, можеме ефикасно да бараме елементи по нивната вредност – на пример, да провериме дали во дрвото постои вредност еднаква на 10, да додадеме нова вредност, итн.
Самата податочна структура го има добиено името "бинарно дрво" бидејќи, секој елемент, покрај неговата вредност, има и до две “деца”. Притоа, вредноста на левото дете (доколку такво постои) е помала од вредноста на неговиот родител, додека вредноста на десното дете (доколку такво постои) е поголема. За првиот (најгорниот) елемент, уште велиме и дека е корен на дрвото.
Кога бараме одреден елемент во дрвото, многу лесно и ефикасно се спроведува потрагата по таа вредност - почнувајќи од најгорниот елемент, ја споредуваме бараната вредност со онаа на елементот кај кој се наоѓаме и се движиме лево (доколку бараната вредност е помала од елементот) или десно (доколку бараната вредност е поголема). Доколку, при движењето низ дрвото и правењето на споредбите, ја најдеме бараната вредност - завршуваме со постапката. Доколку дојдеме до ситуација да веќе не постојат деца кон кои можеме да отидеме, тоа значи дека, во дрвото, таква вредност не постои.
Бинарно дрво е исклучително популарна податочна структура, и таа, во реалноста, се користи за решавање на многу проблеми. Голем дел од нив, како броење на единствени елементи и дупликати, ќе бидат споменати уште во првото наредно предавање.
Интересно, сите операции кои може да се направат од страна на приоритетен ред, може да се направат и кај бинарно дрво. Кај некои програмски јазици, приоритетен ред се имплементира користејќи бинарно дрво. На пример, за да го најдеме елементот со најголем приоритет кај бинарно дрво, потребно е само да се движиме надесно во дрвото, т.е. секогаш да бараме елементи поголеми од тековниот. Во таков случај, кога веќе нема да можеме да се движиме надесно, елементот каде што се наоѓаме е оној кој има најголема вредност (приоритет). Нормално, сите овие операции имаат временска сложеност O(logN).
Хеш табела
Хеш табелите се користат многу често, при решавање на разни проблеми. Тие претставуваат ефикасна податочна структура за проблеми како проверка дали одреден елемент припаѓа во одредено множество; или имплементација на речник – каде под одреден клуч (на пример, збор) се наоѓа вредност (значењето на тој збор). Главната предност која хеш табелите ја имаат во однос на другите податочни структури е тоа што, истите, овозможуваат ефикасен пристап до вредности, преку користење на нивните клучеви.
Како споредба, кај низите можеме ефикасно да пристапиме до одреден елемент, преку негово пронаоѓање користејќи ја позицијата на тој елемент во низата (array[0], array[5], итн), и тоа во константно време O(1). Но, кај низите, постои ограничување дека позициите се лимитирани со големината на низата (ако имаме низа од 1000 елементи, можно е да се запишуваат вредности само кај позициите 0 до 999). Со помош на хеш табели пак, можеме да запишуваме вредности под различни клучеви (table[12312], table["word"], итн), и тоа повторно, како и кај низите, во константно време O(1).
Хеш табелите се веќе имплементирани за нас во новата верзија на програмскиот јазик C++ (и во други модерни јазици). Сепак, да се обидеме да сфатиме како тие навистина функционираат. Имено, во позадина, хеш табелите користат низа за чување на самите вредности, но, со еден дополнителен трик – т.н. хеш функција. Хеш функција е функција која што претвора клуч (12312, “word”, итн) во цел број кој што е валидна позиција во одредена низа (на пример, доколку низата е со големина 10000, хеш функцијата враќа број од 0 до 9999). Често користени хеш функции е земањето модул (остаток при делење), земање на одредени битови, итн. Бидејќи хеш функциите се така направени да секогаш враќаат ист резултат за ист клуч, можеме да вршиме операции врз хеш табелата користејќи клучеви – барање на елемент, запишување на нова вредност, итн. На пример, нека за клучот “word”, хеш функцијата враќа 17. Тогаш, во позадина, хеш табелата чита и запишува вредности во нејзината низа од вредности, на позиција array[17]. Во сите модерни програмски јазици, ова се спроведува транспарентно за нас, па нема потреба да размислуваме како хеш табелата функционира, колку е голема низата во позадина итн. Едноставно, само велиме table[“word”] = 200, и се останато го прави самиот програмски јазик.
Иако хеш функциите брзо пресметуваат позиција, нема потреба да користите хеш табела кога обична низа е доволна за решавање на проблемот (ако знаете дека треба да чуваме 1000 елементи, а е доволно да ги идентификуваме нив со нивната позиција 0-999). Во таков случај, низата е најдобра структура, и ќе функционира делумно побрзо (бидејќи нема потреба од повикување на хеш функција за пресметка на вистинската позиција).
Хеш табелите често решаваат слични проблеми како и бинарните дрва - на пример, пронаоѓање на дупликати, броење колку пати се појавува одреден елемент, имплементација на речник (кај бинарните дрва, ова се прави преку чување на пар од податоци [клуч, и вредност] во секој елемент од дрвото [почнувајќи од најгорниот елемент - коренот, па надолу], и споредба на клучевите при движење низ дрвото). Притоа, хеш табелите се често онаа структура која е поефикасна при решавање на истите проблеми - бидејќи кај нив, пристапот е во константно време O(1), наместо логаритамско O(logN), како кај бинарните дрва. Но, кај бинарните дрва постои правило како овие елементи се подредени, и можно е ефикасно да се најде најмалиот елемент (движење лево), најголемиот елемент (движење надесно), следниот елемент поголем од одредена вредност, итн. Доколку не е потребна ниту една од тие додатни операции кои зависат од распоредот на елементите, за решавање на овие проблеми најчесто ќе користиме хеш табели, иако и двете податочни структури се често доволно ефикасни – и O(1) и O(logN) се сметаат за сложености кои се прифатливи.